大模型行业快速增长
根据相关组织的数据预测,在人工智能技术持续创新和商业化应用不断深化的背景下,全球大模型市场空间正在高速扩大。
2028年,全球大模型市场规模有望达到1095亿美元,较2023年的210亿美元增长超过5倍。在此期间的2022-2028年,复合年增长率预计可达47.12%。可以看出,未来几年全球企业和组织对大模型的商业需求将持续快速增长。
与全球市场类似,我国大模型市场前景同样广阔。据预测,到2028年中国大模型市场规模将达到1179亿元人民币,较2023年的147亿元增长近8倍。2022-2028年我国大模型市场的复合年增长率有望达到60.11%。可以预见,国内大模型技术和应用将在各方面取得长足进步。
此外,多模态大模型的出现也为AI赋能带来了全新机遇。通过文本、语音、图像等多种模式训练的大模型,可支持更加智能和人性化的交互应用。第一财经数据显示,我国多模态内容市场规模到2025年将超过830亿美元,2018-2025年复合增长率高达65.02%。可以预计,医疗、教育、娱乐等领域都将从中受益。
整体来看,全球和中国的大模型市场正处于高速增长期,技术创新和商业化应用潜力巨大。随着政策和资本的持续支持,预计未来数年相关市场规模将继续保持较快扩张态势。


AI模型从单模态向多模态发展
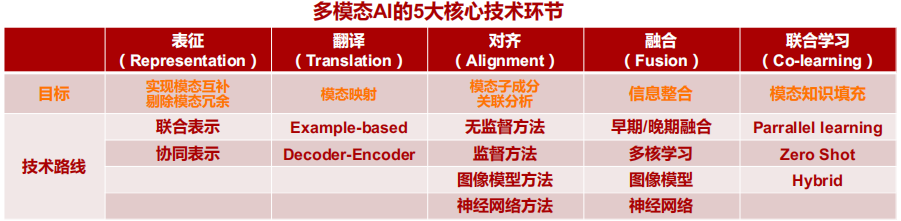
多模态AI通过融合多项技术,能够解决复杂的问题,主要技术分别为表征、翻译、对齐、融合和联合学习,通过这5大技术环节实现模态互补、模态映射、模态成分关联分析、信息整合和模态知识填充。
1、多模态表征技术。这是指对不同模态的数据,如文本、语音、图像等进行数字化编码,提取其语义特征表示,为后续建模和训练奠定基础。常用的表征技术有词向量、图像特征提取等。
2、多模态翻译技术。这是指在不同模态之间进行转换,例如文本转语音,图像转语音,以实现多模态之间的互操作。这需要保证转换后的语义含义不变。
3、多模态对齐技术。这是指建立不同模态信号之间语义一致的对应关系,找到它们在时间和空间维度上的匹配,以支撑后续的多模态融合。
4、多模态融合技术。这是指设计算法,对不同模态的表征进行整合,充分挖掘表征之间的互补信息,获得更加全面丰富的联合表示。常用方法有拼接等。
5、多模态联合学习技术。这是指设计联合的神经网络模型架构,在多个模态的监督下联合进行表示学习或决策学习,以获得跨模态泛化的模型。
通过这5大核心技术的协同运用,多模态AI系统可以实现跨文本、语音、图像、视频等模态的互操作转换,统一表示与联合建模,从而比单一模态系统拥有更强大的理解、推理和决策能力。

Soar技术与性能分析
2024年2月,Open AI 发布AI视频模型Soar,其强大的技术实力和实际视频效果将AI视频发展推向了新的高度。
从技术角度看,Soar底座基于diffusion和 transformer结构。diffusion的核心是马尔可夫链,通过逐步去噪声的过程,从一个随机分布中生成目标分布的样本。举例来说,假如有一张脸的照片,逐步添加噪点直到不可认,再通过神经网络逆向去噪,还原成一张脸,最终获得数据潜在分布的结构。
Transformer的核心是注意力机制,通过捕捉数据之间长距离依赖关系,提高自然语言和视觉等领域的性能。举个例子来说,当你看一张脸时,并不会记住这张脸全部信息,而是关注焦点,比如眼睛和嘴巴。Transformer在语言、视觉和图像生成等多个领域都表现出良好的拓展能力。

Sora的技术原理区别于其他AI视频模型,因此体现出更强的性能:
在视频时长处理能力方面,Sora模型表现突出,它能轻松处理高达60秒的长视频,远超其他模型只能处理2-4秒甚至更短视频片段的限制。这使得Sora模型更胜任处理时间跨度大、内容复杂的视频任务。
在对世界的理解能力方面,Sora模型展现出深刻的认知能力。它不仅能准确理解数字世界的各种元素和关系,还支持数字环境的仿真和预测。相较其他模型在这些方面表现有限,Sora模型拥有接近人类水平的对世界的建模与推理能力。

在判断物体一致性和持续性方面,Sora模型也表现突出。它能高度准确地识别和跟踪物体,正确理解物体之间的关系与变化。这是评价AI系统对真实世界理解的关键指标之一。
在模型架构上,Sora模型采用了领先的Transformer结构,这使其在处理语言和文本理解任务上更胜一筹。相比之下,其他模型使用的结构如U-Net等在这些方面表现相对较弱。
在输出质量上,Sora可生成高达1080P的高清视频,达到业内最高标准,使其在高质量视频生成应用中占据优势。
Sora还具备数据驱动的视频生成能力和与数字世界高度自然交互的能力。它可根据输入数据自动输出匹配的视频,并可无缝连接和交互数字环境中的各元素。这些功能使Sora模型在沉浸式内容生成、虚拟现实等领域应用前景广阔。


国内外AI视频模型对比
目前国内外在大模型视频领域积极竞赛,Soar一骑绝尘,诸如Runway Gen2、Pika、Stable Video Diffusion(SVD)等算法或工具也各具特色。
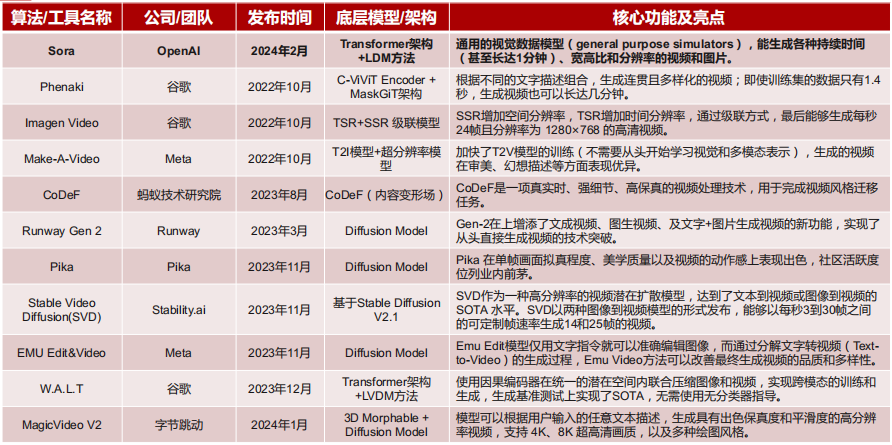
以Stable Video Diffusion(SVD)为例。2023年11月,StabilityAI发布了视频生成式大模型Stable Video Diffusion(SVD)。Stable Video Diffusion是一种潜在扩散模型,支持文本生成视频和图像生成视频以及物体从单一视角到多视角的3D合成。
SVD模型之所以能生成质量很高的视频,主要基于以下三个方面:
超大规模的数据集
SVD使用了包含58亿个视频剪辑的大数据集进行训练。为了确保数据质量,SVD采用了多种自动化方法对视频进行评估筛选,如检测镜头切换、评估运动表征、生成文字描述、计算美学质量等。这么大规模且高质量的数据,使得SVD模型学到的视频知识更加丰富。
多阶段的训练策略
SVD先后进行了图像预训练、视频预训练和视频微调三个训练阶段。先初始化图像生成模型,然后在大数据集上学习视频的时序表征,最后在小规模精确数据集上微调。这种策略逐步提取和训练不同粒度的知识,有利于生成高保真视频。
多模式的生成任务
SVD可以进行多种视频生成任务,比如根据文本描述生成视频场景,根据一张图片生成后续镜头,生成多个视角的3D视频等。这些生成任务像是不同的练习,使得模型在生成视频方面更加全面和娴熟。
 AI视频商业化展望
AI视频商业化展望
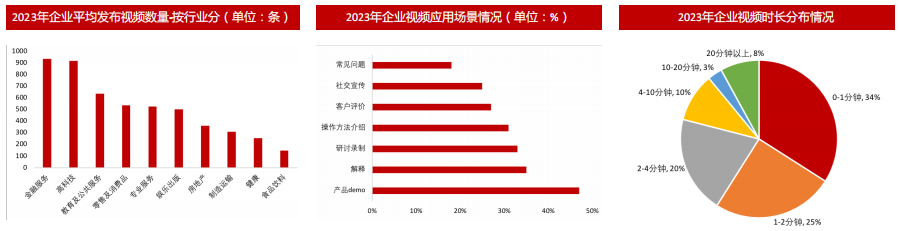
大模型从技术出现到技术落地再到商业化应用,必然要经历一个漫长的阶段,就目前来看,AI无论是无论是在企业发布视频满足宣传需求还是个人创作者能够以更低门槛生成视频方面都有广阔的前景。从企业视频应用场景看,相当比例的企业将视频营销应用于产品Demo(47%)、名词解释(35%)、活动回放(33%)、操作方法介绍(31%)等场景,而个人则更多的使用低门槛工具实现视频的高质量创作。
就目前市场情况来看,国内外已经有Runway、Synthesia等公司尝试商业化路径。Runway 目前提供基础版、标准版、专业版、无限版、企业版五个版本的产品。希望探索Runway的个人用户可免费试用基础版,可以生成3个视频项目,Gen-1生成的视频长达4秒,Gen-2长达16秒,清晰度720P,提供3个视频编辑器。最主流的订阅方式是标准版,年费方案下12美金/月(按月订购15美金/月),从内容生成单价看,Gen-1模型下每秒视频的生成价格为0.14美元(合$8.4/min),而Gen-2模型的价格为每秒0.05美元(合$3/min),而文本转语音的价格为每50词0.01美元。
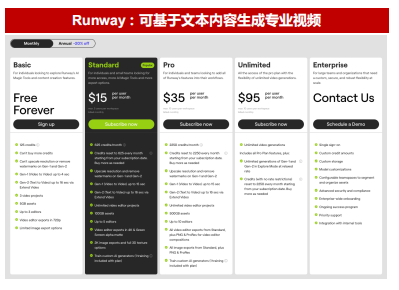
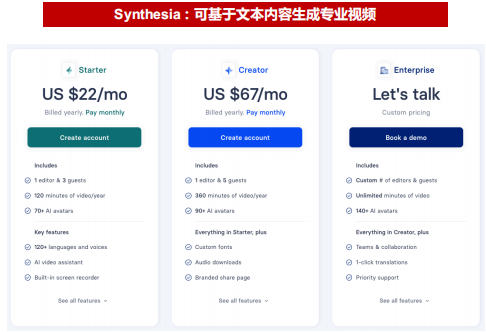
Synthesia 目前分为个人、创作者和企业三个版本的产品。年费方案下个人用户的收费为22美元/月(合每年264美元),个人方案每月只支持 10 分钟的视频制作。创作者用户的收费为67美元/月(合每年804美元),创作者方案每月支持 30分钟的视频制作。
针对企业用户,Synthesia 则根据公司需求设定定制化的收费方案,费用主要与使用者数量相关。
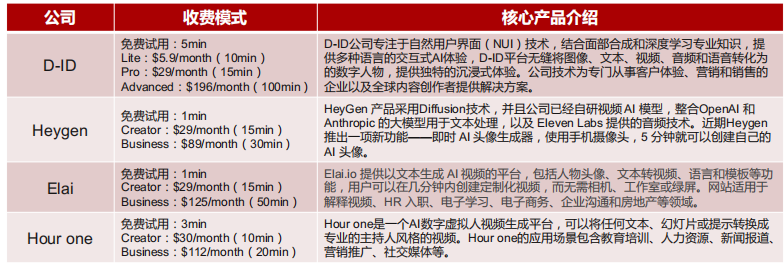
除Synthesia、Runway外,目前海外布局AIGC视频生成的厂商还有D-ID、Heygen、Elai等,这些厂商基于积累的虚拟人素材库和视频模板库,可根据客户的需求快速生成视频内容,应用场景主要集中在产品营销宣传、客户服务、内部培训等场景,视频生成价格大多约为每分钟2美元。
展望未来,在文生图领域,虽然创业门槛较低,但商业模式仍然存在一些疑问。国内C端用户对付费的意愿相对较低,而B端则更加依赖于与特定场景的结合,这就要求提供定制化的解决方案。因此,需要建立针对不同客户需求的图片生成引擎,这对于工程化能力提出了很高的要求。结合技术发展路径,我们认为未来的文生AI视频领域将呈现以下趋势:
对于B端来说,文生视频对企业来说吸引力较大,能够极大提升工作效率和质量,但从AI视频发展和应用来说,企业追求更加精细化和定制化AI视频,这一方向AI大模型公司通过收取流量或者按次收费的模式进行运营。
对于C端来说,普通用户对视频的精度要求不高,但同样有很大的吸引力,能够将自己的想法即时生成视频,但C端的普遍付费意识不高。AI大模型公司更多通过免费的形式来吸引用户,用户达到一定数量后,通过广告的形式来实现业务收入。