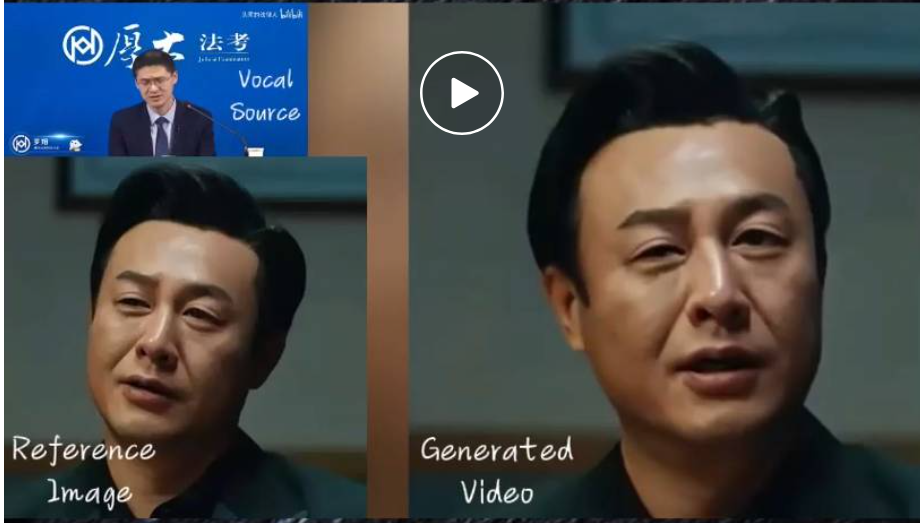
最近,以 OpenAI Sora 为代表的文生视频模型又火了起来。
而除了文本生成视频之外,以人为中心的视频合成也一直是研究的焦点,比如专注于说话人头部(Talking Head)的视频生成,它的目标是根据用户提供的音频片段来生成面部表情。
从技术上来看,生成表情需要捕获说话人微妙和多样化的面部动作,由此对此类视频合成任务提出了重大挑战。
传统方法通常会对最终的视频输出施加限制,以简化任务。比如,一些方法使用 3D 模型来限制面部关键点, 另一些方法则从原始视频中提取头部运动的序列以指导整体运动。这些限制虽然降低了视频生成的复杂性,但也往往限制了最终面部表情的丰富度和自然度。
在阿里智能计算研究院近日的一篇论文中,研究者通过关注音频提示和面部动作之间的动态和细微联系,来增强说话人头部视频生成的真实度、自然度和表现力。
研究者发现,传统方法往往无法捕捉完整范围的说话人表情和不同说话人独特的面部风格。基于此,他们提出了 EMO(全称为 Emote Portrait Alive)框架,该框架可以直接利用音频 - 视频合成方法,不再需要中间 3D 模型或面部标志。

-
论文标题:EMO: Emote Portrait Alive- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
就效果而言,阿里的方法可以确保整个视频的无缝帧过渡,并保持身份一致,进而产生表现力强和更加逼真的角色化身视频,在表现力和真实感方面显著优于当前 SOTA 方法。
比如 EMO 可以让 Sora 生成的东京女郎角色开口唱歌,歌曲为英国 / 阿尔巴尼亚双国籍女歌手 Dua Lipa 演唱的《Don't Start Now》。
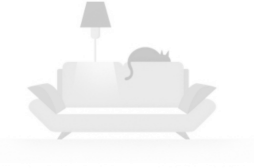
EMO 支持包括英文、中文在内等不同语言的歌曲,可以直观地识别音频的音调变化,生成动态、表情丰富的 AI 角色化身。比如让 AI 绘画模型 ChilloutMix 生成的小姐姐唱陶喆的《Melody》。

EMO 还能让角色化身跟上快节奏的 Rap 歌曲,比如让小李子来一段美国说唱歌手 Eminem 的《哥斯拉》(Godzilla)。

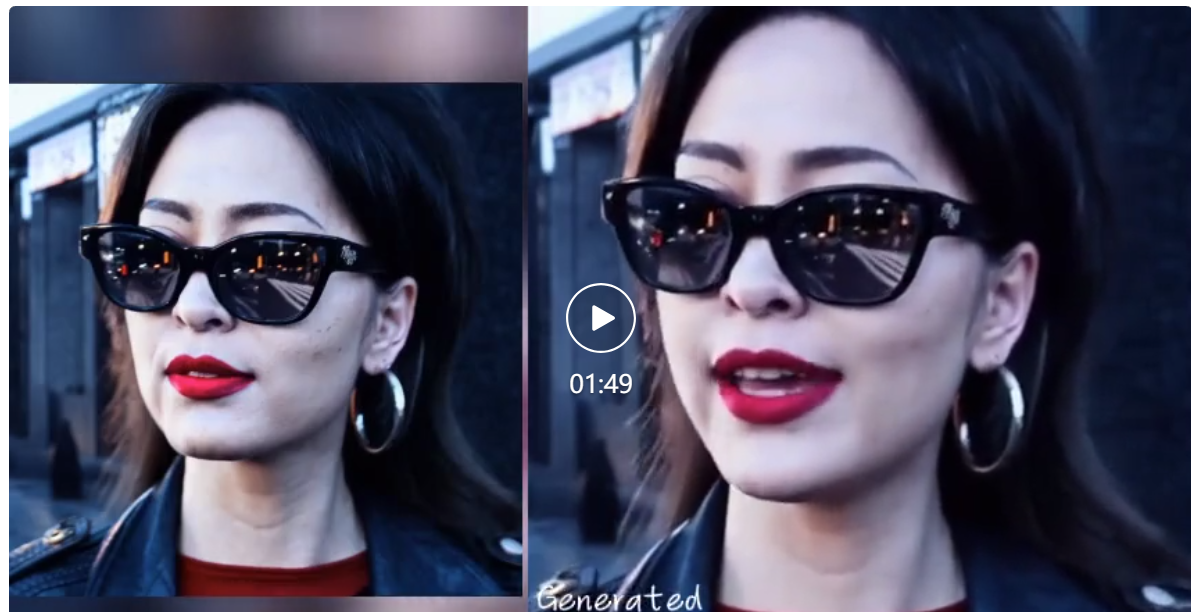
当然,EMO 不仅仅能让角色开口唱歌,还支持各种语言的口语音频,将不同风格的肖像画、绘画以及 3D 模型和 AI 生成的内容制作成栩栩如生的动画视频。比如奥黛丽赫本的谈话。
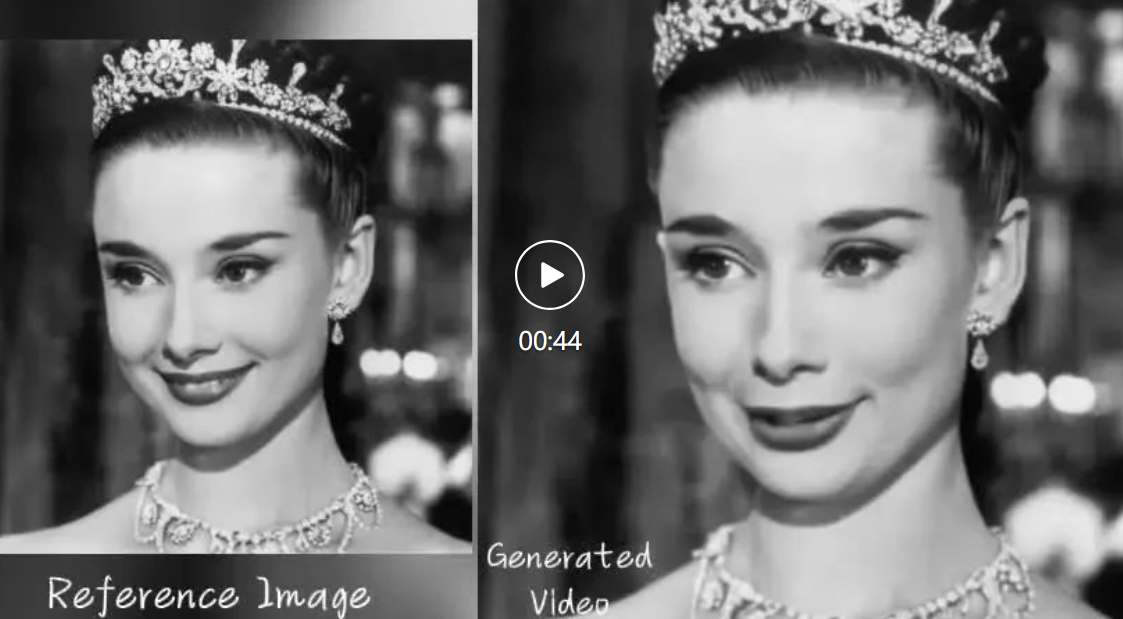
最后,EMO 还能实现不同角色之间的联动,比如《狂飙》高启强联动罗翔老师。
方法概览
给定人物肖像的单张参考图像,本文方法可以生成与输入语音音频片段同步的视频,还能保留人物非常自然的头部运动和生动的表情,并且与所提供的声音音频的音调变化相协调。通过创建一系列无缝的级联视频,该模型有助于生成具有一致身份和连贯运动的长时间说话肖像视频,这对于现实应用至关重要。
网络 Pipeline
方法概览如下图所示。主干网络接收多帧噪声潜在输入,并尝试在每个时间步骤中将它们去噪为连续的视频帧,主干网络具有与原始 SD 1.5 版本相似的 UNet 结构配置,具体而言
-
与之前的工作相似,为了确保生成帧之间的连续性,主干网络嵌入了时间模块。
-
为了保持生成帧中人像的 ID 一致性,研究者部署了一个与主干网络并行的 UNet 结构,称为 ReferenceNet,它输入参考图像以获取参考特征。
-
为了驱动角色说话时的动作,研究者使用了音频层来编码声音特征。
-
为了使说话角色的动作可控且稳定,研究者使用脸部定位器和速度层提供弱条件。
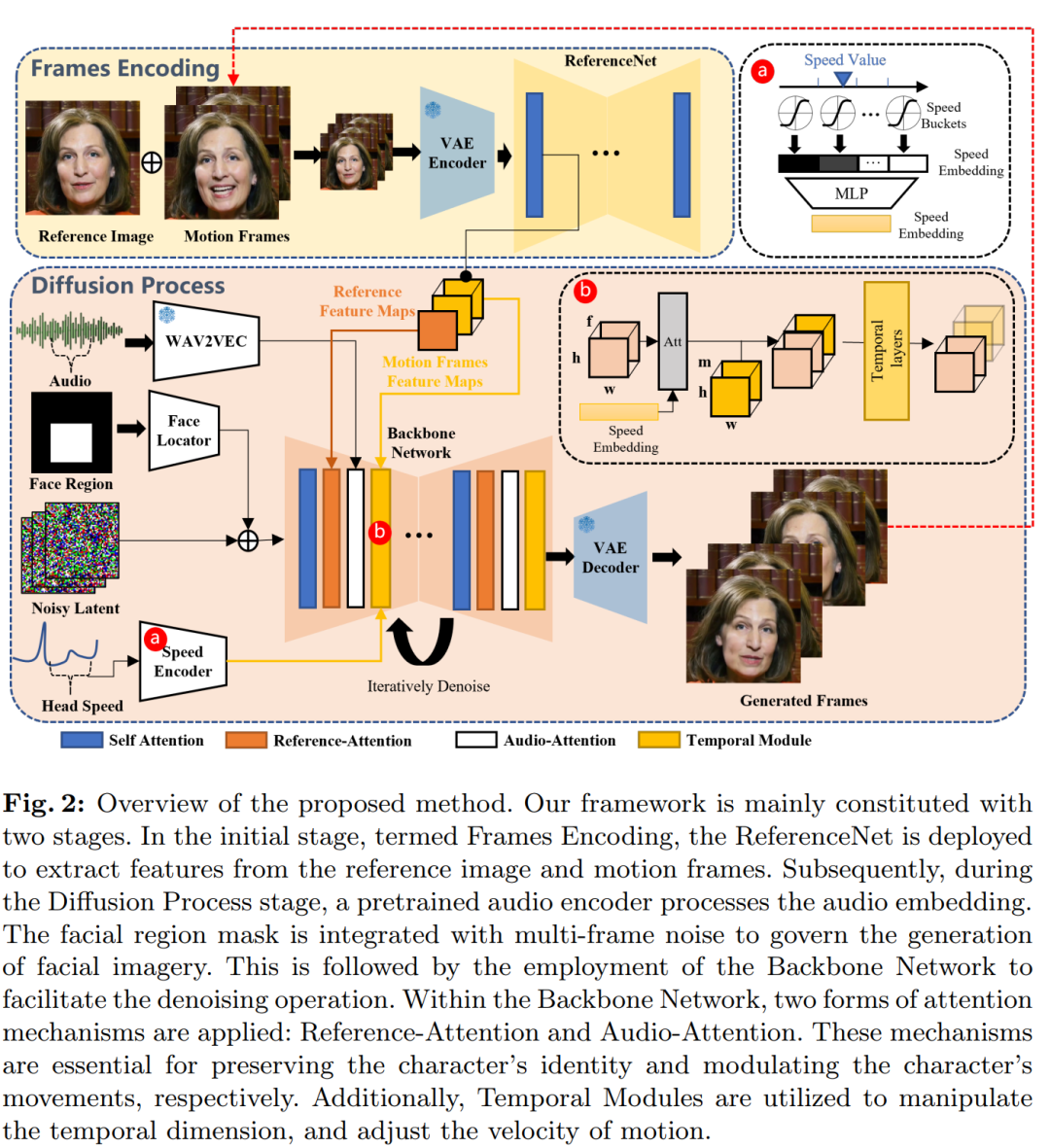
对于主干网络,研究者没有使用提示嵌入,因此,他们将 SD 1.5 UNet 结构中的交叉注意力层调整为参考注意力层。这些修改后的层将从 ReferenceNet 获取的参考特征作为输入,而非文本嵌入。
训练策略
训练过程分为三个阶段:
第一阶段是图像预训练,其中主干网络、ReferenceNet 和面部定位器被纳入训练过程中,在这个阶段,主干网络以单一帧作为输入,而 ReferenceNet 处理来自同一视频剪辑的不同的、随机选择的帧。主干网络和 ReferenceNet 都从原始 SD 初始化权重。
在第二阶段,研究者引入了视频训练,并且加入了时间模块和音频层,从视频剪辑中采样 n+f 个连续帧,其中起始的 n 帧为运动帧。时间模块从 AnimateDiff 初始化权重。
最后一个阶段集成了速度层,研究者只在这个阶段训练时间模块和速度层。这种做法是为了故意忽略训练过程中的音频层。因为说话人的表情、嘴部运动和头部运动的频率主要受音频的影响。因此,这些元素之间似乎存在相关性,模型可能会根据速度信号而不是音频来驱动角色的运动。实验结果表明,同时训练速度层和音频层削弱了音频对角色运动的驱动能力。
实验结果
实验过程中参与比较的方法包括 Wav2Lip、SadTalker、DreamTalk。
图 3 展示了本文方法与先前方法的比较结果。可以观察到,当提供单个参考图像作为输入时,Wav2Lip 通常会合成模糊的嘴部区域并生成以静态头部姿态和最小眼部运动为特征的视频。就 DreamTalk 而言,其结果可能会扭曲原始面孔,也会限制面部表情和头部运动的范围。与 SadTalker 和 DreamTalk 相比,该研究提出的方法能够生成更大范围的头部运动和更生动的面部表情。

该研究进一步探索了各种肖像风格的头像视频生成,如现实、动漫和 3D。这些角色使用相同的声音音频输入进行动画处理,结果显示,生成的视频在不同风格之间产生大致一致的唇形同步。

图 5 表明本文方法在处理具有明显音调特征的音频时能够生成更丰富的面部表情和动作。例如下图第三行,高音调会引发角色更强烈、更生动的表情。此外,借助运动帧还可以扩展生成的视频,即根据输入音频的长度生成持续时间较长的视频。如图 5 和图 6 所示,本文方法即使在大幅运动中也能在扩展序列中保留角色的身份。


表 1 结果表明本文方法在视频质量评估方面具有显著优势: