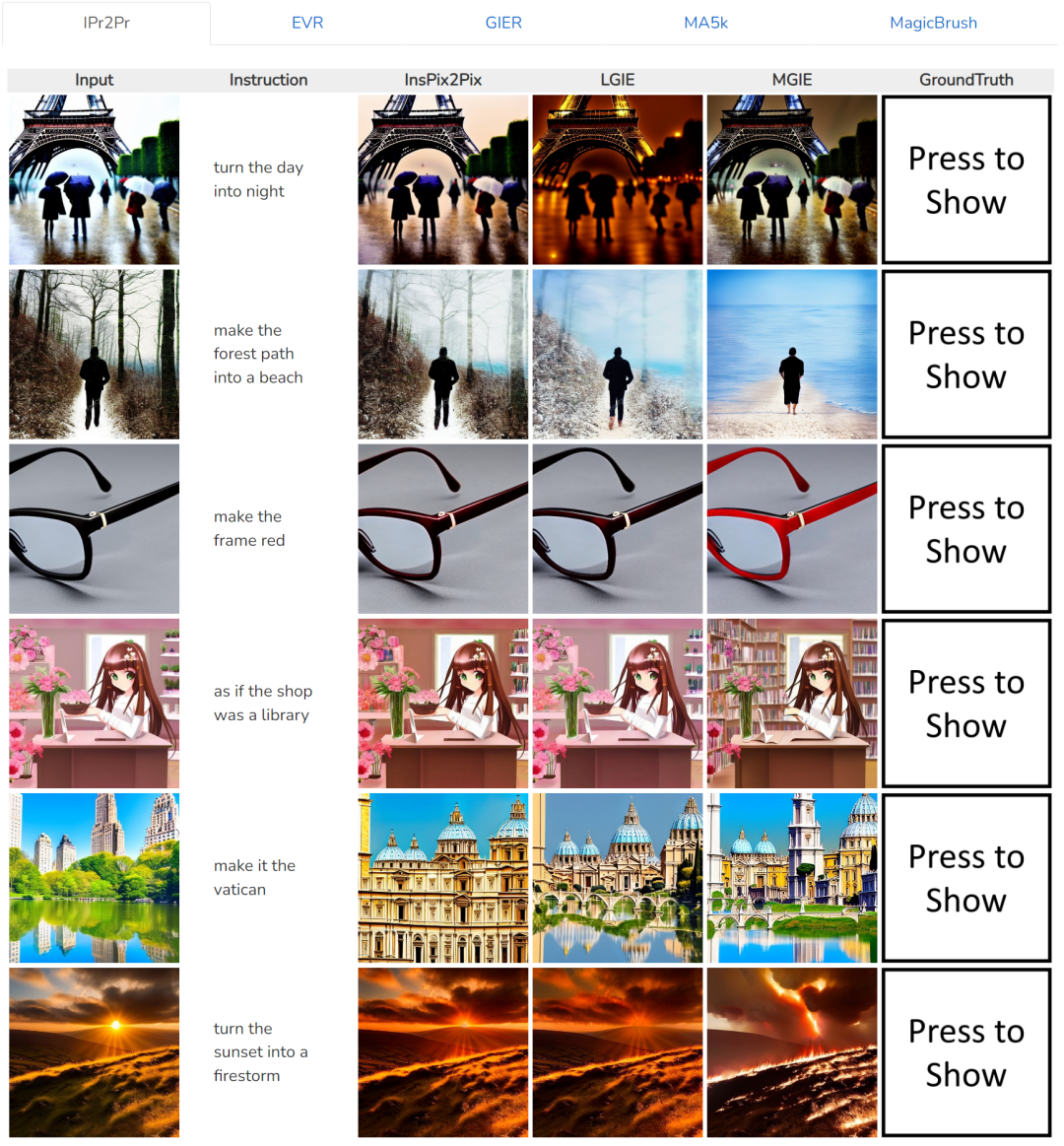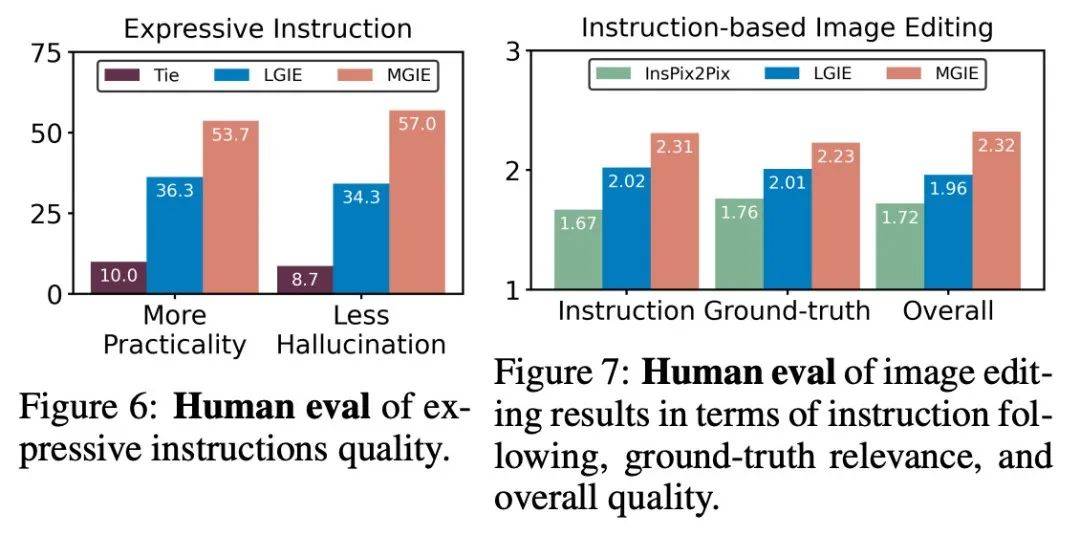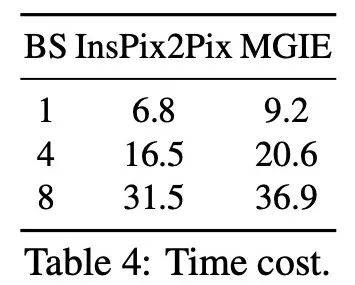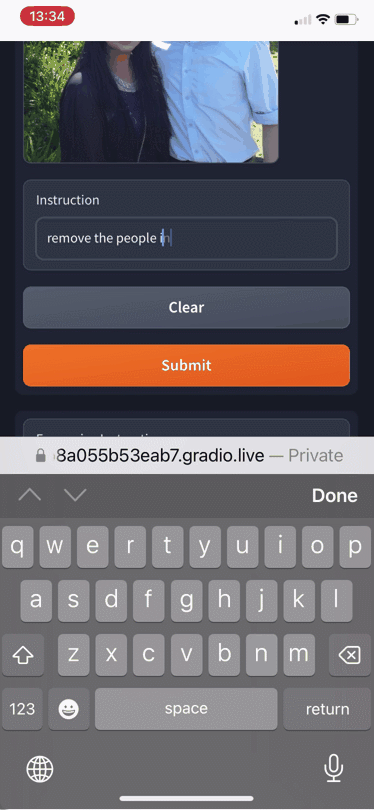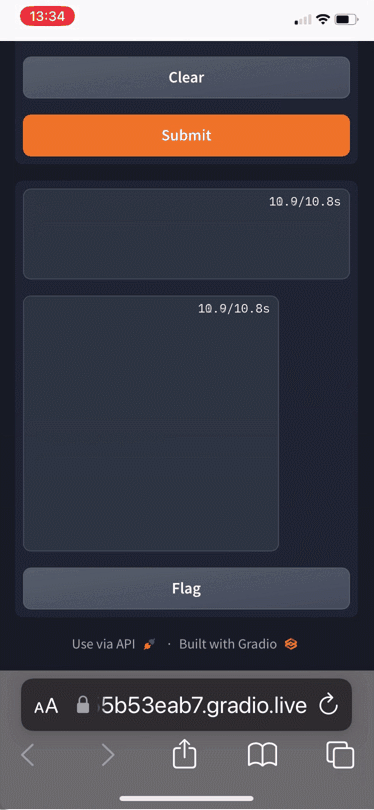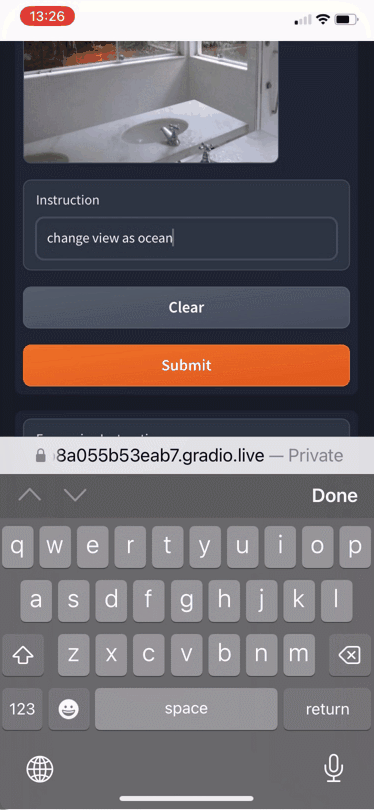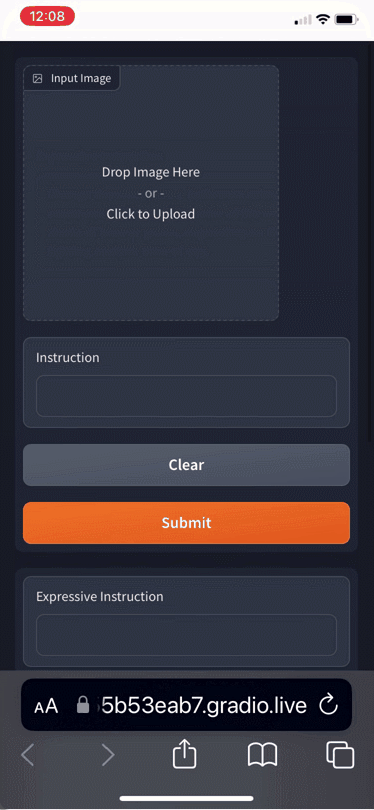
 在桌子上添加披萨
在桌子上添加披萨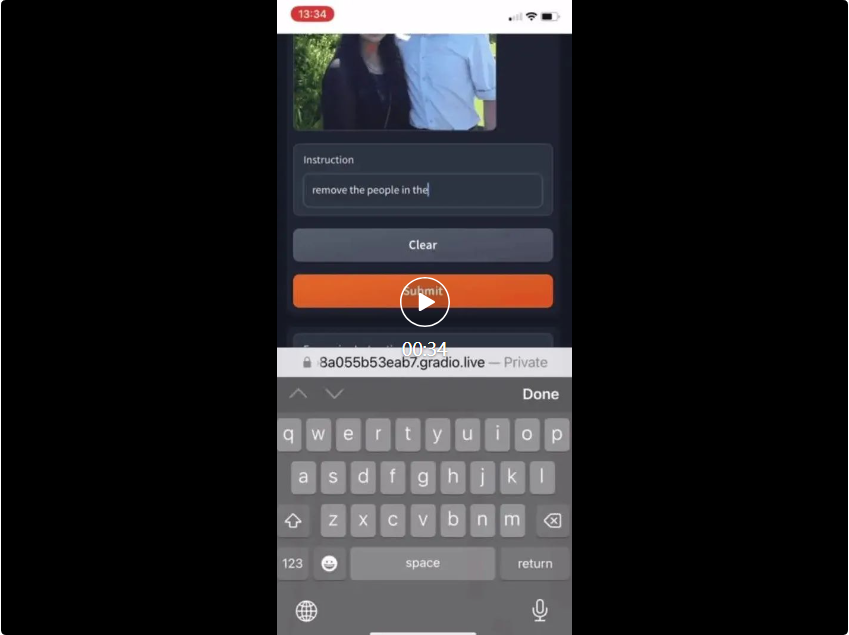

-
论文标题:Guiding Instruction-based Image Editing via Multimodal Large Language Models -
论文链接: https://openreview.net/pdf?id=S1RKWSyZ2Y -
项目主页: https://mllm-ie.github.io/


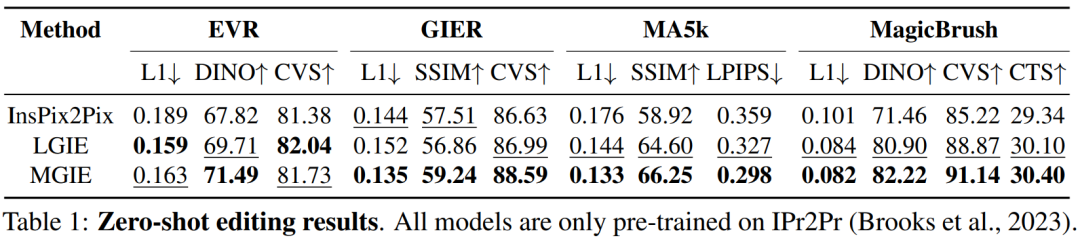
 。对于那些不精确的指令,MGIE 中的 MLLM 会进行学习推导,从而得到简洁的表达指令 ε。为了在语言和视觉模态之间架起桥梁,研究者还在 ε 之后添加了特殊的 token [IMG],并采用编辑头(edit head)
。对于那些不精确的指令,MGIE 中的 MLLM 会进行学习推导,从而得到简洁的表达指令 ε。为了在语言和视觉模态之间架起桥梁,研究者还在 ε 之后添加了特殊的 token [IMG],并采用编辑头(edit head)
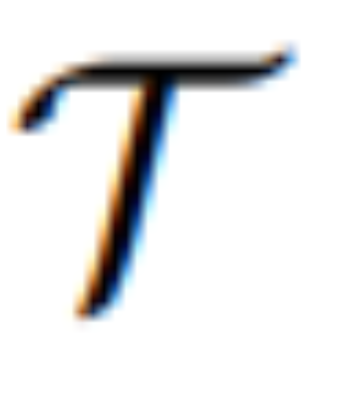 对它们进行转换。转换后的信息将作为 MLLM 中的潜在视觉想象,引导扩散模型
对它们进行转换。转换后的信息将作为 MLLM 中的潜在视觉想象,引导扩散模型
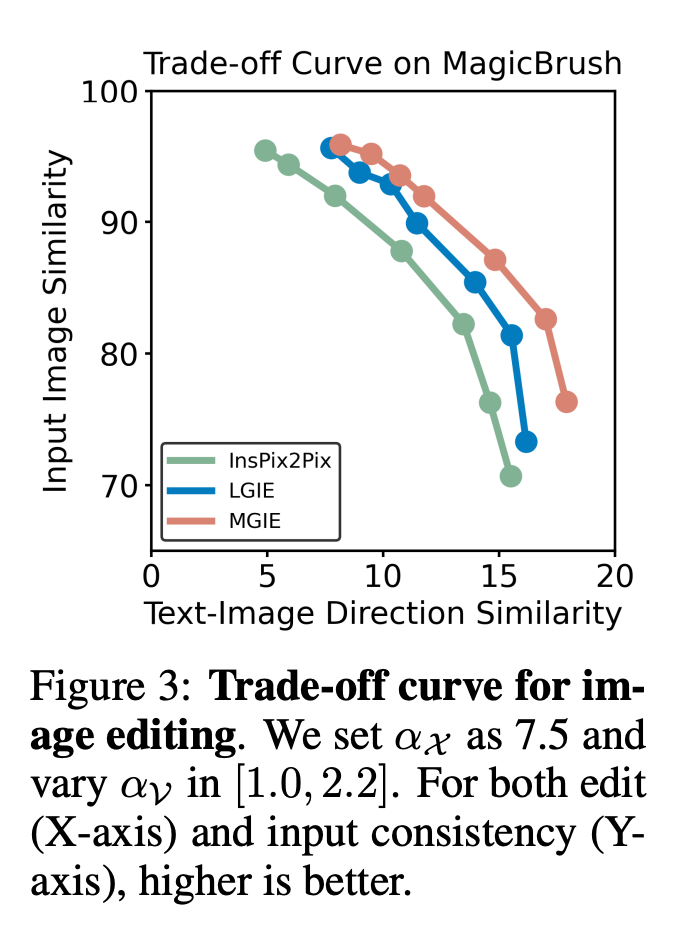
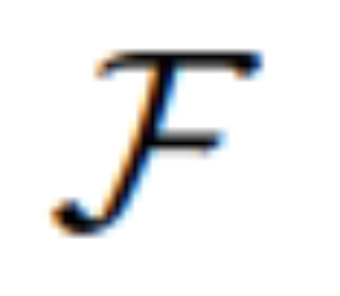 实现预期的编辑目标。然后,MGIE 能够理解具有视觉
感知的模糊命令,从而进行合理的图像编辑(架构图如上图 2 所示)。
实现预期的编辑目标。然后,MGIE 能够理解具有视觉
感知的模糊命令,从而进行合理的图像编辑(架构图如上图 2 所示)。
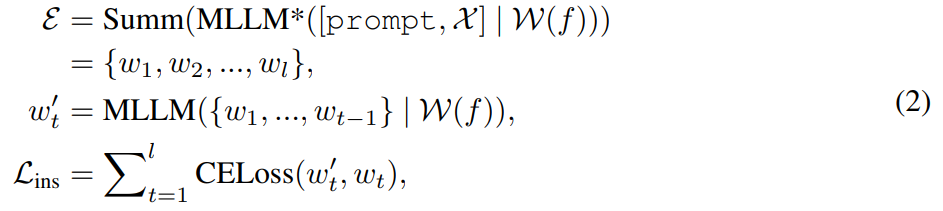
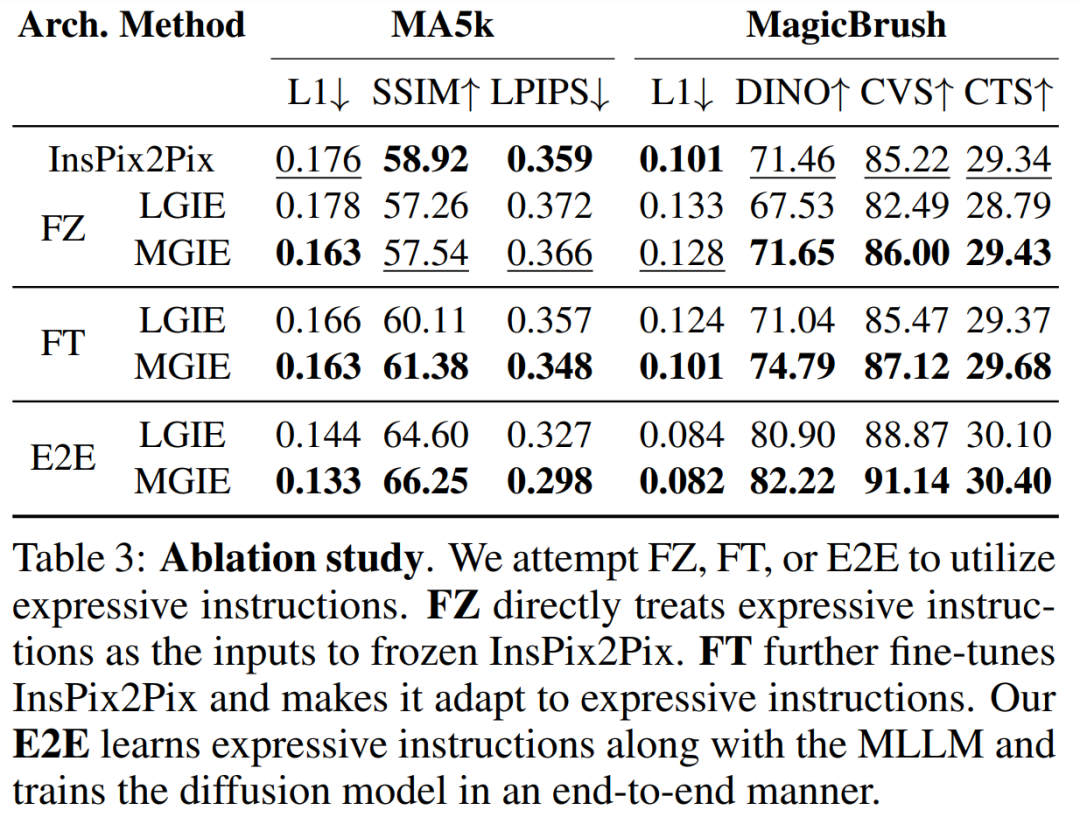
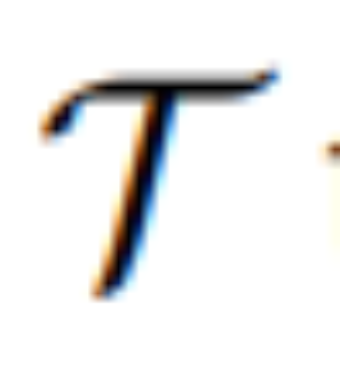 将 [IMG] 转化为实际的视觉引导。其中
将 [IMG] 转化为实际的视觉引导。其中
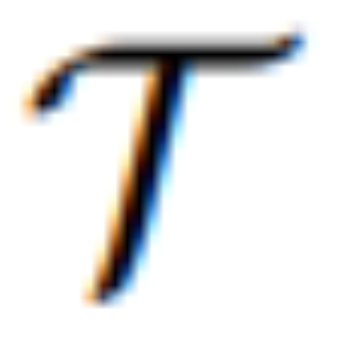 是一个
序列到序列模型,它将来自 MLLM 的连续视觉 tokens
映射到语义上有意义的潜在 U = {u_1, u_2, ..., u_L} 并作为编辑引导:
是一个
序列到序列模型,它将来自 MLLM 的连续视觉 tokens
映射到语义上有意义的潜在 U = {u_1, u_2, ..., u_L} 并作为编辑引导:

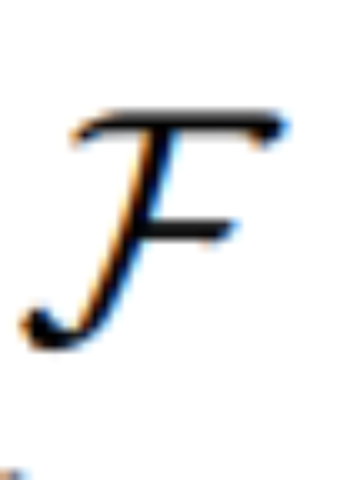 ,该模型在包含变分自动编码器(VAE)的同时,还能解决潜在空间中的去噪扩散问题。
,该模型在包含变分自动编码器(VAE)的同时,还能解决潜在空间中的去噪扩散问题。
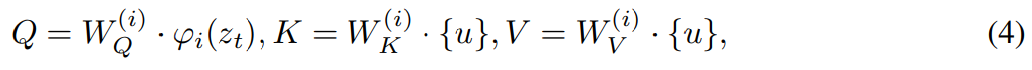
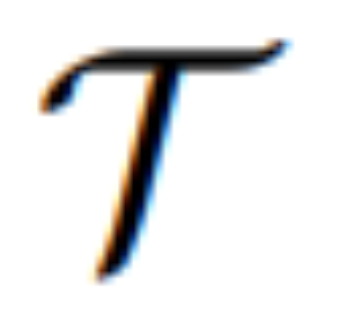 转变其模态并引导
转变其模态并引导
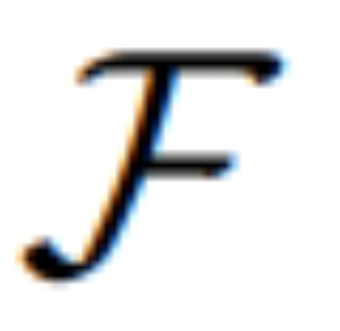 合成结果图像。编辑损失 L_edit 用于扩散训练。由于大多数
权重可以被冻结(MLLM 内的
自注意力块),因而可以实现
参数高效的端到端训练。
合成结果图像。编辑损失 L_edit 用于扩散训练。由于大多数
权重可以被冻结(MLLM 内的
自注意力块),因而可以实现
参数高效的端到端训练。