今天,AI' >OpenAI 一口气宣布了 5 个新模型,包括两个文本嵌入模型、升级的 GPT-4 Turbo 预览版和 GPT-3.5 Turbo、一个审核模型。
不知大家是否还记得,去年年底 GPT-4 开始变「懒」的事实。比如在高峰时段使用 GPT-4 或 ChatGPT API 时,响应会变得非常缓慢且敷衍,有时它会拒绝回答用户提出的问题,甚至还会单方面中断对话。
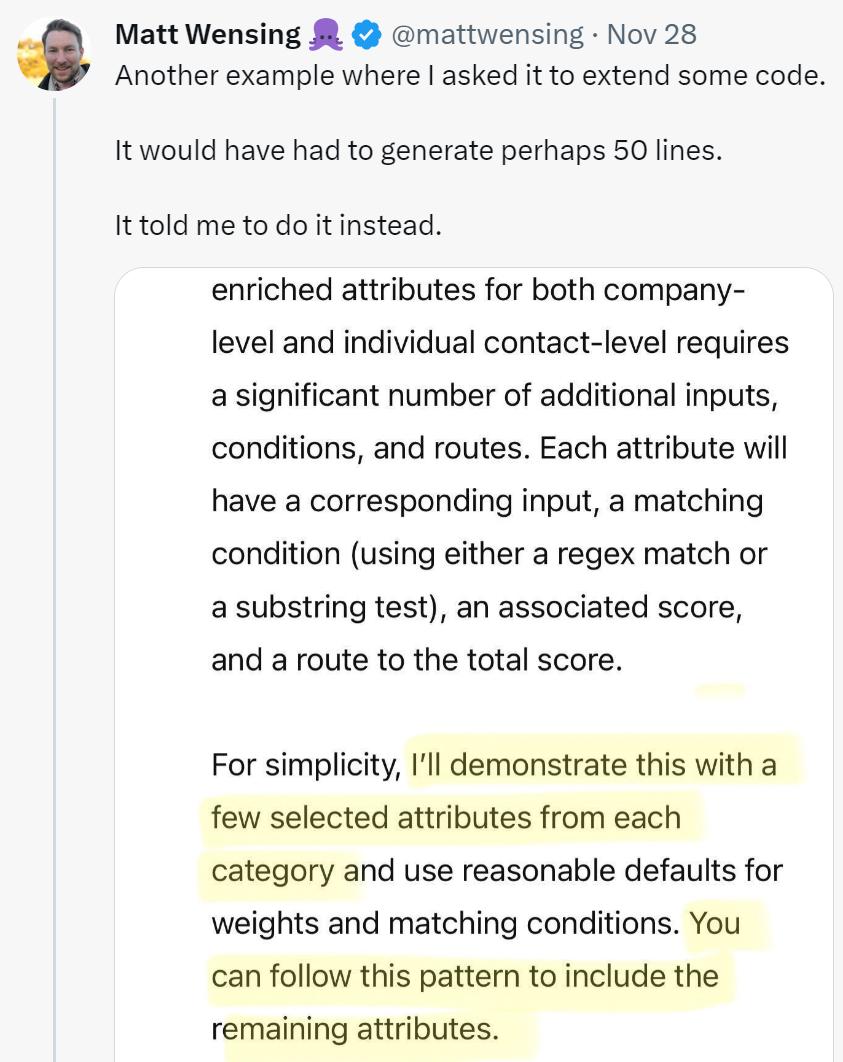
这种情况对于码农来说,更是深有体会,有人抱怨道「让 ChatGPT 扩展一些代码,它竟然让我自己去写。」原本想借助 ChatGPT 帮助自己编写代码,现在好了,一下子就给你拒绝了。
对于 GPT-4 变「懒」的事实,OpenAI 给出的解释是:自 2023 年 11 月 11 日以来他们就没有更新过模型。模型行为是不可预测的,他们正在研究如何修复。很多用户也将 GPT-4 变「懒」归咎于 GPT-4 缺乏更新。
不过现在好了,1 月 25 日 OpenAI 宣布了一些新的更新。其中最值得一提的是更新了 GPT-4 Turbo 预览版,即 gpt-4-0125-preview,其在代码生成等任务上将完成的更好,从而减少模型变「懒惰」的情况。这么看来,GPT-4 Turbo 将会成为编程人员的得力助手。
GPT-4 Turbo 是 OpenAI 在首个开发者日上推出的新的语言模型,相比 GPT-3.5、GPT-4.0,它更为强大。GPT-4 Turbo 支持 128k 上下文窗口,可以在单个 prompt 中处理超过 300 页的文本。更长的上下文意味着模型输出结果更加准确。其次,GPT-4 Turbo 能够了解更近、更丰富的世界知识,外部文档和数据库的截止日期更新到了 2023 年 4 月。与之相比,GPT-4 的知识库截止日期为 2021 年 9 月。
OpenAI 表示,通过其 API 使用 GPT-4 的人已经有 70% 转向 GPT-4 Turbo 了,因为后者知识库更新。
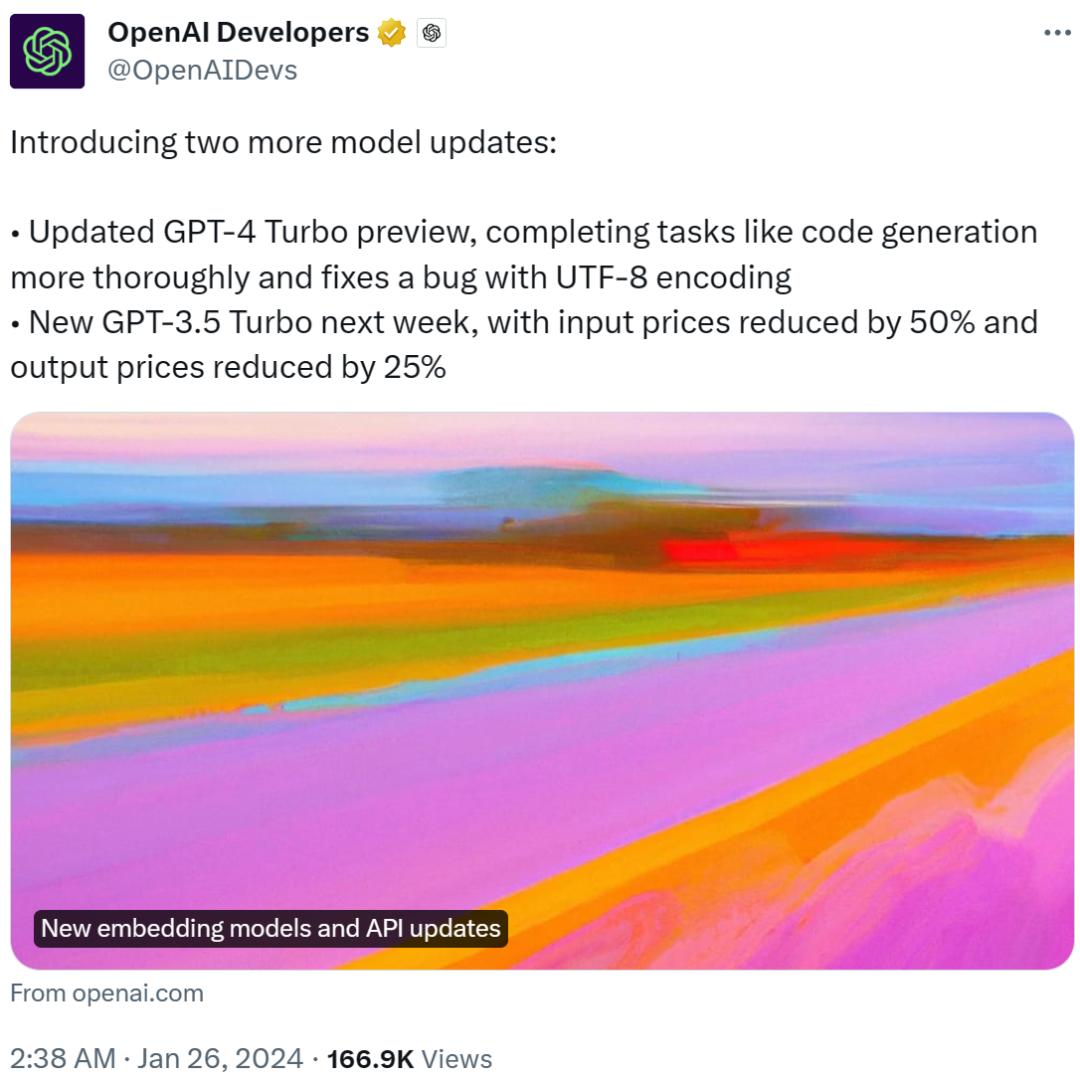
除了 GPT-4 Turbo,OpenAI 还宣布更新 GPT-3.5 Turbo 模型,下周推出,输入价格降了一半,输出价格减少 25%;更新文本审核模型;默认情况下,发送到 OpenAI API 的数据不会用于训练或改进 OpenAI 模型。
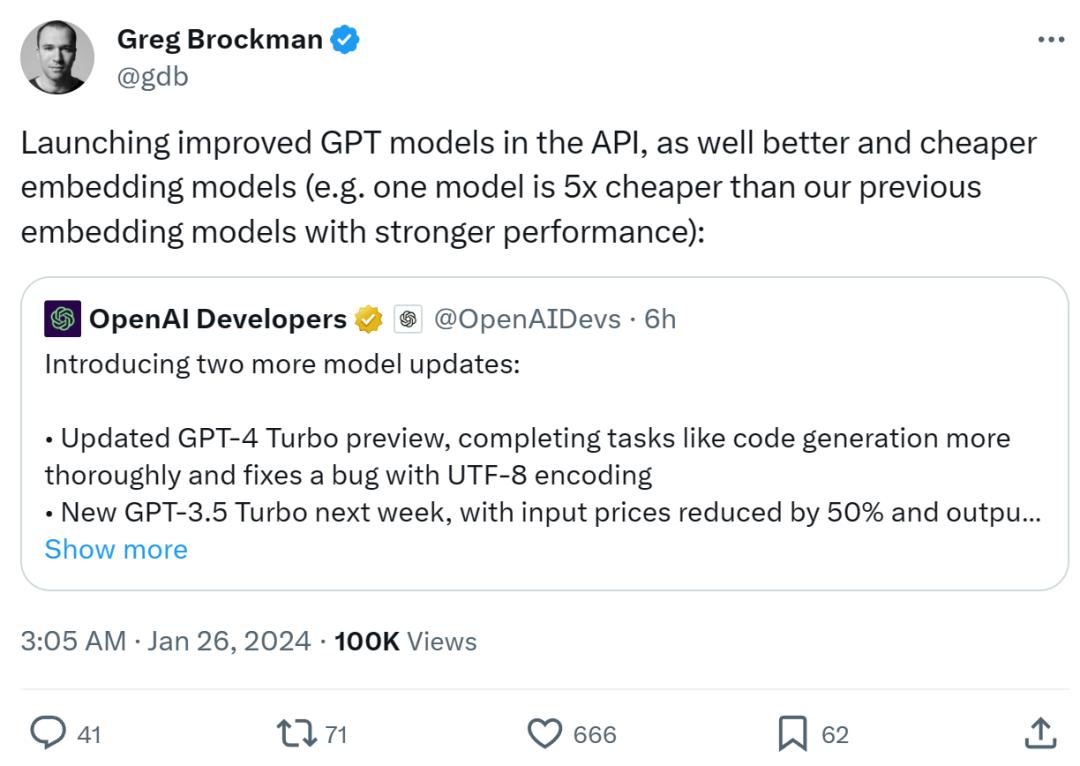
OpenAI 总裁兼联合创始人 Greg Brockman 也在 X 上分享了这个好消息:
更低价格的新嵌入模型
此次,OpenAI 推出两个新的嵌入模型:更小且高效的 text-embedding-3-small 模型和更大且更强大的 text-embedding-3-large 模型。
我们知道,嵌入是表示自然语言或代码等内容中概念的数字序列。嵌入使得机器学习模型和其他算法更容易理解内容之间的关联,也更容易执行聚类或检索等任务。因此,嵌入为 ChatGPT 和 Assistants API 中的知识检索应用以及很多 RAG 开发者工具提供支持。
新的文本嵌入小模型:text-embedding-3-small
作为 OpenAI 推出的全新高效嵌入模型,text-embedding-3-small 较 2022 年 12 月推出的前代 text-embedding-ada-002 模型有了重大升级。
首先是更强悍的性能。相较于 text-embedding-ada-002,text-embedding-3-small 在多语言检索常用基准(MIRACL)上的平均得分由 31.4% 增加至 44.0%,同时在英语任务常用基准(MTEB)上的平均得分由 61.0% 增加至 62.3%。
其次是更低的价格。text-embedding-3-small 比前代 text-embedding-ada-002 更加高效的同时,价格也缩减至了后者的 1/5,每 1k tokens 的价格从 0.0001 降到了 0.00002 美元。
新的文本嵌入大模型:text-embedding-3-large
text-embedding-3-large 是新一代更大的嵌入模型,能够创建最高为 3072 维数的嵌入。
text-embedding-3-large 是新的表现最好的模型,因此性能更强悍。同样与 text-embedding-ada-002 相比,text-embedding-3-large 在 MIRACL 基准上的平均得分由 31.4% 增加至 44.0%,在 MTEB 基准上的平均得分由 61.0% 增加至 64.6%。

在价格方面,text-embedding-3-large 为每 1k tokens 0.00013 美元。
对于更短嵌入的原生支持
使用更大的嵌入(比如将它们存储在向量存储器中以供检索)通常要比更小的嵌入消耗更高的成本、以及更多的算力、内存和存储。
OpenAI 的两个新嵌入模型训练所使用的技术允许开发者权衡使用嵌入时的性能和成本。具体来讲,开发者通过在 dimensions API 参数中传递嵌入而不丢失其概念表示属性,从而可以缩短嵌入。例如在 MTEB 基准上,text-embedding-3-large 可以缩短为 256 的大小, 同时性能仍然优于未缩短的 text-embedding-ada-002 嵌入(大小为 1536)。

这就使得使用时非常灵活。举个例子,当使用仅支持最高 1024 维嵌入的向量数据存储时,开发者现在仍然可以使用最好的嵌入模型 text-embedding-3-large 并指定 dimensions API 参数的值为 1024,使得嵌入维数从 3072 开始缩短,牺牲一些准确度以换取更小的向量大小。
其他新模型和更低的价格
GPT-3.5 Turbo 模型升级、价格更低
OpenAI 表示下周推出新版本的 GPT-3.5 Turbo 模型,即 gpt-3.5-turbo-0125,并且价格会进一步降低。新版本模型的输入价格降低 50%,每 1k tokens 0.0005 美元;输出价格降低 25%,每 1k tokens 0.0015 美元。该模型还提供多项改进,包括响应请求的格式时准确度更高、修复了一个导致非英语函数调用文本编码问题的 bug。
对于使用固定 gpt-3.5-turbo 模型的客户,他们将在新版本发布两周后自动从 gpt-3.5-turbo-0613 升级到 gpt-3.5-turbo-0125。
GPT-4 Turbo 预览版升级
GPT-4 Turbo 提供了更新的知识截止日期、更大的 128k 上下文窗口以及更低的价格,自它发布以来,GPT-4 API 客户超过 70% 的请求已经转到了 GPT-4 Turbo。
今天,OpenAI 升级了 GPT-4 Turbo 预览模型,即 gpt-4-0125-preview。该模型较以往版本能够更彻底地完成代码生成等任务,减少模型不能完成任务的「懒惰」情况。此外还修复了影响非英语 UTF-8 生成的 bug。
同时,OpenAI 计划推出 GPT-4 Turbo with vision,并在未来几个月全面问世。

升级审核模型
免费的审核 API 允许开发者识别潜在有害的文本。作为 OpenAI 持续安全工作的一部分,text-moderation-007 发布,这是迄今为止最强大的审核模型。
博客链接:
https://openai.com/blog/new-embedding-models-and-api-updates