事实上,当英伟达在11月13日宣布推出H200张量核心GPU的时候,并没有让人感到很意外。
毕竟8月30日,英伟达就发布了旗下GH200 Grace Hopper将要搭载HBM3e的消息,目的就是为了下一个张量核心的GPU产品在性能有着绝对的优势。但是当黄仁勋站在台上,大声念着屏幕上H200的详细参数时,除了夸张,就只剩下夸张。
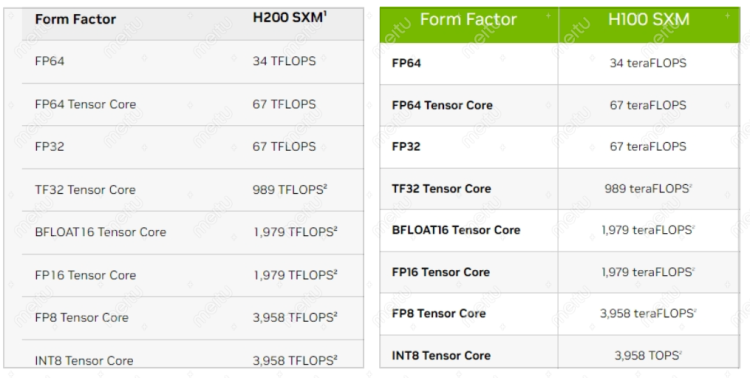
简单过一下参数,H200的显存是141GB,带宽是每秒4.8TB。因为此次推出的是SXM版本,也就是带一个高带宽插座版本。所以对比H100的SXM版本,显存从80GB提升76%,带宽从每秒3.35TB提升了43%。但这不是最主要的,无论是H100还是H200,它都是专注于人工智能复杂计算的,所以在业务方面,Llama2 700亿参数的模型推理速度提高了90%,GPT-3 1750亿参数的推理速度提高了60%。
这就让人不禁好奇,因为从浮点计算能力来说,那肯定是数字越大越厉害。但是从面板来看,同样为SXM版本的H100和H200,无论是FP64还是其他精度,两者皆是完全相同的。要知道H100的单PCIe版本整个浮点精度都要比SXM版本低,因此它的带宽只有每秒2TB,上文提到H100的SXM可是有每秒3.35TB,浮点精度之间的差距会带来性能差异,那精度相同的两张卡,咋就也产生差异了?
左为H200,右为H100
内功叫做HBM3e
这就好像武侠里面那老头,看起来手无缚鸡之力,一出手直接能打翻成年壮汉,这便是“内力”。H200这次采用的是和H100相同的hopper架构,最大的区别是搭载了上文已经提到过的HBM3e。先拆分一下这几个英文字母,HBM全称为高带宽内存,是一种利用三维同步动态随机存取技术(SDRAM)构建的内存接口,指的是利用垂直概念来扩展内存同时大幅度增加堆栈内处理速度。说白了就是过去内存里面大家都是一字长蛇阵排开,第一个处理完业务才能让下一个进来,没利用到空间,只是利用到平面。而到了HBM这里,设立了多窗口服务,只不过是垂直于地面建立的,排队速度更快。
另一方面,动态随机访问存储器,也就是常说的DRAM和SDRAM相比,SDRAM是在DRAM的架构基础上增加同步和双区域(Dual Bank)的功能,使得微处理器能与SDRAM的时钟同步,所以SDRAM执行命令和传输资料时相较于DRAM可以节省更多时间。排队窗口增加了,排队速度也加快了,因此整体效率自然而然升高了。最后到了3e,3就是第三代架构,e就是第三代架构的威力加强版,和游戏里DLC差不多一个概念。
英伟达H100采用的是SK海力士在2022年6月生产的HBM3(PCIe版H100用的是HBM2e,这里补充说明一下),这款内存产品堆栈内存带宽是每秒819GB。HBM3e,则是对HBM3在同一架构下,对用料、逻辑、算法的升级,内存带宽足足提升了25%,来到每秒1TB。那么回到一开始提出的问题,Llama2模型的运行大抵都遵守每10亿参数耗费3到5GB内存的原则,不过这个是会随版本更新、算法优化而变少的,毕竟开发者也为了防止内存溢出,进而发生不可预估的错误。等于说是,内存越大运行效率越快。
不过这才提升了25%啊!别急,英伟达的狠活还在后面。都说内练一口气,可别忘了,还要外练筋骨皮。H200和H100都是采用Hopper架构这个不假,然而英伟达为前者其进行了“武装”——TensorRT-LLM。英伟达TensorRT-LLM是由TensorRT深度学习编译器组成,包括优化的内核、预处理和后处理步骤以及多GPU/多节点通信原语。
外功叫做TensorRT-LLM
TensorRT-LLM的工作原理类似于“高斯求和”的故事,别的小朋友还在算等差数列依次相加的时候,高斯直接掏出一个公式很快算出了结果。TensorRT-LLM就相当于是这么一个公式,以软件优化的方式帮助GPU快速解决复杂计算。以H100为例,使用TensorRT-LLM后的H100,在对一些媒体网站进行文章摘要时的工作效率,比使用前快出整整1倍。而在700亿参数的Llama2上,前者比后者快77%。这个东西英伟达没敢在H100上大肆宣扬,直至今年8月时才拿出来大晒。
事实上英伟达耍了一个花招,在官网对比上,H200 SXM对比的是没有使用TensorRT-LLM的H100 SXM,当然这是后话,毕竟本身TensorRT-LLM也不是为H100准备的。综上,内功上英伟达有了HBM3e,外功上有了TensorRT-LLM,因此在没有计算精度变化的前提下,才能在性能上高出上代产品那么多。
2023年年初的时候,英伟达收盘在140多块左右,发布完了H200,截止至写稿,收盘在489块,距离年初涨了230%。行了,老黄这回算彻底疯狂了,我要是他估计我比他还狂呢。可我说停停,今年6月的时候一位英伟达一直以来的死对头,黄仁勋大舅罗伯沐的孙女,也就是黄仁勋的表外甥女苏姿丰站了出来。她拿出了一块AMD用来挑战H200地位的GPU——MI300X。

苏姿丰与MI300X
别看MI300X依然使用HBM3内存,但是AMD来了一招“加量不加价”,MI300X的内存达到了191GB,比H200还足足高了35%。191GB放在GPU里是个怎么回事?H100有一个版本叫做H100 NVL,这个版本非常简单粗暴,它是用两个PCIe版本的H100直接焊在一起,产生1+1>2的效果,这也才让内存来到188GB,MI300X单单一块就是191GB。然而大也有大的不好,MI300X额定功率是750W,比H200多了50W。功率和内存不一样,是反着来的,它是越小越好,越低的额定功率代表设备的维护成本越低,越耐用。一般来说,人工智能实验室不会只使用一块GPU产品,他们大多都是复数购买,每块MI300X都比H200多50W额定功率的话,最后很可能聚沙成塔,导致失去竞争力。
对于英伟达来说还有一个头疼的问题,中国几家互联网巨头一直是A100和H100的忠实客户,不过美国随后很快就禁止了向中国销售这两块GPU产品。雪上加霜的是,随着美国在2023年10月发布的禁令,A100和H100的中国定制版A800和H800,也要在11月17日以后禁止向中国销售了。从财报上来看,英伟达数据中心大约25%的收入是来自于中国,H200不出意外的话应该很快就会被列为禁止向中国出售的产品之一。